
Criando um Modelo de Dados de Direitos Musicais: Identificadores, Entidades e Padrões de Relacionamento para Desenvolvedores
Um modelo de dados de direitos musicais robusto é a base para fluxos de trabalho precisos de edição, licenciamento e royalties em qualquer sistema de produção. Este guia oferece a desenvolvedores, arquitetos de dados e profissionais de música um projeto alinhado aos padrões e pronto para produção para identificadores, entidades canônicas, padrões de relacionamento e técnicas práticas para reconciliação, proveniência e direitos com limite de tempo. Você encontrará esquemas concretos, exemplos de SQL e Neo4j e mapeamentos para DDEX, ISWC/ISRC e IPI para ajudar a implementar e validar fluxos de trabalho do mundo real.
1. Cenário de Identificadores e Quando Confiar em Cada Identificador
Ponto direto: Trate os identificadores como atributos definidos, não como chaves absolutas. Cada identificador carrega uma autoridade limitada, perfil de confiabilidade e modos de falha; seu registro canônico deve registrar qual fonte emitiu o identificador e o quão confiante você está de que ele se aplica.
Identificadores principais, autoridade e produtores típicos
- ISWC - Emitido pela CISAC e agências de registro; o escopo é a obra musical ou composição. Use para registros de Obra canônicos. Consulte documentos da CISAC ISWC.
- ISRC - Emitido sob a orientação da IFPI para gravadoras e titulares de direitos; o escopo é a gravação de som. Use para registros de Gravação e reconciliação de entrega. Consulte o guia ISRC da IFPI.
- IPI/CAE - Identificadores de partes atribuídos via PROs para compositores e editores musicais; melhor para correspondência de partes entre sistemas.
- ISNI - Registro de identidade de colaborador mais amplo, útil para colaboradores não relacionados à execução e vinculação de metadados.
- GRid - Identificador para lançamentos e pacotes de lançamento; usado por distribuidores e agregadores.
- DDEX ERN / RIN - Identificadores de nível de mensagem e referências de recursos usados em trocas de metadados; autoritativo para proveniência de feed. Consulte os padrões DDEX.
- CWR - Formato de registro de obras em massa usado entre editores musicais e PROs; fonte de dados ISWC e de participação em massa quando disponível.
Como isso falha na prática: Os identificadores estão faltando, aplicados incorretamente ou duplicados. As gravadoras às vezes emitem ISRCs para versões de faixas incorretas. As obras geralmente não são registradas e carecem de ISWC. As partes são representadas por IDs locais conflitantes nas exportações PRO. Confiar cegamente em qualquer identificador único causa corrupção silenciosa de divisões e fluxos de pagamento.
Dicas de validação e normalização: Sempre valide o formato - por exemplo, ISWC tem um dígito de verificação e padrão de prefixo - e armazene a autoridade emissora e o timestamp. Enriqueça os identificadores em relação aos registros autoritativos, sempre que possível, em vez de confiar no que veio no feed. Registre o resultado do enriquecimento e limite a taxa de erros para evitar incompatibilidades silenciosas.
Estratégia de chave canônica e heurísticas de fallback
Regra de chave canônica: Use uma chave canônica composta por ___CODE0 mais CODE1 e CODE_2___ para rastreabilidade. Não faça de um único identificador externo a única chave primária para suas tabelas de Obra ou Gravação.
Hierarquia de fallbacks e correspondência: Prefira a correspondência exata do identificador. Se ausente, execute a pesquisa de registro autoritativa, depois a correspondência de metadados de alta confiança usando título normalizado + IPI do colaborador, depois a impressão digital acústica e, finalmente, a revisão humana. Cada etapa deve gravar uma pontuação de confiança e um ponteiro de proveniência para o payload bruto.
Exemplo concreto: Um DDEX ERN de entrada chega sem ISWC. Seu pipeline deve tentar uma pesquisa CISAC/PRO por ISWC por IPI e título do colaborador, então consultar o MusicBrainz para gravações e impressões digitais correspondentes e, se ainda não resolvido, criar um registro de Obra provisório marcado ___CODE0 com o ERN como CODE1___. Sinalize o registro para avaliação manual se a confiança estiver abaixo do limite.
Priorize a proveniência do identificador sobre a presença do identificador - registrar quem emitiu o ID e quando é tão importante quanto o próprio ID.
Conclusão: construa sua canonicalização em torno da autoridade e proveniência, não em torno da ilusão de um ID universal. Próxima consideração - projete propriedade e declarações com limite de tempo para referenciar esses registros de identificador composto.
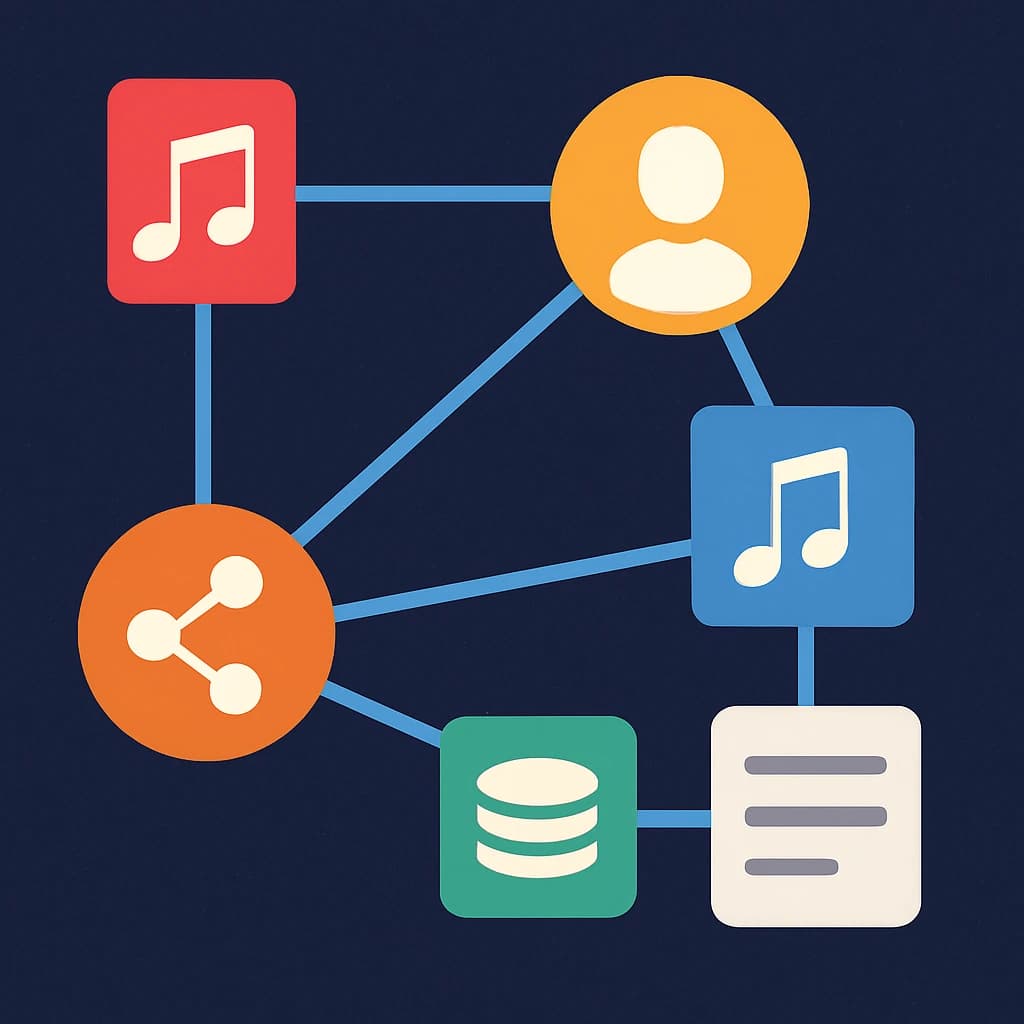
2. Entidades Canônicas para Modelar e Seus Atributos Principais
Auditoria gratuita
Curioso para saber quanto dinheiro sua música já gerou em royalties?
Comece com entidades, não com documentos. Um modelo de dados de direitos musicais robusto trata as entidades canônicas como a fonte da verdade para licenciamento, relatórios e reconciliação downstream - não os formatos de arquivo de entrada. Projete cada entidade em torno de suas responsabilidades operacionais: identificação, proveniência e declarações com limite de tempo.
Entidades canônicas principais (o que armazenar e por que)
- Obra — ___CODE0, CODE1, *ISWCCODE2originalLanguageCODE3firstReleaseDateCODE4contributorsCODE5partyIdCODE6roleCODE7IPICODE_8___canonicalTitles` (variantes normalizadas)
- Gravação — ___CODE0, CODE1, *ISRCCODE2durationCODE3audioFingerprintCODE4derivedFromWorkIdsCODE5___releaseIds` (muitos)
- Lançamento — ___CODE0, CODE1, CODE2/catalogNumberCODE3releaseDateCODE4labelIdCODE5trackListingsCODE_6___recordingId`)
- Parte — ___CODE0, CODE1, CODE2 (pessoa|organização), CODE3/CODE4, CODE5___ (compositor, editor musical, intérprete), ponteiros de contato e contratuais mantidos em registros locais
- Acordo — ___CODE0, CODE1, CODE2, CODE3, CODE4, CODE5 (links para CODE_6___)
- Instância de Direito — ___CODE0, CODE1 (execução|mecânico|sincronização|distribuição), CODE2, CODE3 flag, CODE4, CODE5, CODE_6___
- Participação de Propriedade — ___CODE0, CODE1, CODE2, CODE3, CODE4, CODE5, CODE6, CODE7, CODE_8___
- Território — Códigos ISO, agregações e agrupamentos comuns usados pela lógica de negócios
- Evento — eventos de uso ou registro (___CODE0, CODE1, CODE2, CODE3___) para proveniência e auditoria
Insight prático: Modele a Participação de Propriedade como numerador/denominador, não como uma porcentagem flutuante. Os campos fracionários evitam o desvio de arredondamento durante a agregação de divisão e preservam a aritmética exata para cálculos de royalties e auditorias.
Trade-off de design: Normalize ___CODE0 e CODE1___ para evitar dados de contato e contrato repetidos, mas desnormalize uma visualização otimizada para leitura (registro canônico em cache) para consultas de pagamento rápidas. Na prática, mantemos tabelas normalizadas estritas para atualizações autoritativas e uma visualização materializada desnormalizada para execuções de royalties em lote.
Exemplo concreto: Ao ingerir um DDEX ERN, crie ou atualize um ___CODE0 com CODE1 e links de CODE2 do colaborador, crie linhas de CODE3 para cada gravação de som com CODE4 e CODE5 e emita registros de CODE6 dos campos de participação do colaborador ERN referenciando o ERN como CODE7. Exemplo de JSON mínimo: CODE_8___.
| Entidade | Atributos de chave mínimos |
|---|---|
| Obra | workId, title, ISWC, contributors[], firstReleaseDate |
| Gravação | recordingId, title, ISRC, duration, fingerprint, derivedFromWorkIds[] |
| Participação de Propriedade | ownershipShareId, ownerPartyId, numerator, denominator, effectiveFrom, sourceRecordId |
Julgamento final: A maioria dos problemas vem da modelagem insuficiente de tempo e proveniência, ou do colapso de Lançamento e Gravação. Modele a validade temporal e as referências de origem desde o primeiro dia; você agradecerá a si mesmo quando precisar responder quem era o proprietário do quê em um período de relatório anterior.
3. Padrões de Relacionamento e Regras de Cardinalidade
Ponto direto: os relacionamentos em um modelo de dados de direitos musicais raramente são um-para-um; projete para muitos-para-muitos por padrão e torne as exceções explícitas e aplicadas.
Arquétipos de relacionamento comuns
| Relacionamento | Cardinalidade típica | Nota de implementação |
|---|---|---|
| Obra ↔ Gravação | Muitos-para-muitos | Use uma tabela de junção work_recording_map com um edge_type (por exemplo, arranjo, cover, sample) e confidence opcional |
| Gravação → Lançamento | Muitos-para-um (a faixa aparece em um registro de lançamento por instância de lançamento) | release_track com track_position e release_catalogue_number para lidar com vários lançamentos |
| Parte ↔ Obra (propriedade) | Muitos-para-muitos via Participação de Propriedade | Armazene participações fracionárias como numerador/denominador e torne as participações com limite de tempo (effectiveFrom/effectiveTo) |
| Acordo → Instância de Direito | Um-para-muitos | Instância de Direito captura rightType, território, exclusividade e prazo; os acordos referenciam essas instâncias |
Regras de cardinalidade que você deve codificar: garanta que, para qualquer Instância de Direito única com escopo para uma obra/território/janela de tempo, o conjunto de registros de Participação de Propriedade ativos represente a divisão autoritativa. Não confie em porcentagens de texto livre em acordos como a fonte da verdade.
- Regra de soma ativa: para cada (workid, righttype, território, janela de tempo) as participações ativas devem somar 1 (ou o total acordado) — valide na ingestão.
- Regra de não sobreposição: as participações de propriedade que são exclusivas não devem se sobrepor no tempo para o mesmo direito e território; modele as sobreposições como transições explícitas com proveniência.
- Regra de tipo de aresta: as arestas de relacionamento precisam de um qualificador tipado (por exemplo, derivedfrom, interpolated, containssample) para que a lógica de royalties downstream possa tratá-las de forma diferente.
Trade-off: impor a aritmética e a não sobreposição no nível da restrição do banco de dados é seguro, mas frágil ao ingerir feeds externos confusos. Na prática, valide e rejeite automaticamente apenas os registros claramente inválidos; sinalize conflitos ambíguos para revisão humana e armazene payloads brutos para permitir correção posterior.
Exemplo concreto: uma gravação de medley contém três composições. Represente isso com três linhas ___CODE0 vinculando a Gravação R123 às Obras W1, W2, W3 e crie registros de Participação de Propriedade para cada compositor com intervalos efetivos vinculados à data de lançamento da gravação. Quando um componente posteriormente reverte para um editor musical anterior, adicione uma nova Participação de Propriedade com um CODE1___ posterior e sourceRecordId apontando para o acordo de reversão.
Julgamento de gráfico vs relacional: use tabelas relacionais e JSONB para registros canônicos e auditáveis e restrições; adicione um índice de gráfico ou réplica Neo4j para travessias rápidas como encontrar todas as gravações derivadas ou redes de editores musicais transitivas. Não modele a proveniência apenas como propriedades de gráfico — mantenha campos com limite de tempo autoritativos no armazenamento canônico para contabilidade.
Importante: trate os atributos territoriais e de exclusividade como partes de primeira classe das chaves de relacionamento — não fazer isso cria pagamentos duplicados silenciosos e dores de cabeça de reconciliação.
Próxima consideração: depois de codificar essas regras de cardinalidade, crie testes automatizados que simulem casos extremos comuns — medleys, samples, direitos de editor musical revertidos e exclusivos com limite de território — e afirme tanto a aritmética das participações quanto os links de proveniência de volta para mensagens de origem como DDEX ERN. Para referência e orientação de mapeamento, consulte os padrões DDEX e armazene payloads brutos conforme descrito na lista de verificação de ingestão canônica em UniteSync.
4. Modelagem de Divisões de Propriedade, Proveniência e Direitos com Limite de Tempo
A propriedade deve ser modelada como declarações imutáveis e auditáveis que são válidas para uma janela de tempo e rastreiam de volta para uma fonte. Trate cada participação como um registro de primeira classe em vez de um campo mutável em uma Obra ou Parte.
Layout de registro prático: crie um registro de ___CODE0 com CODE1, CODE2 (compositor/editor musical/proprietário), CODE3, CODE4, CODE5, CODE6, CODE7 (códigos ISO ou lista de cobertura), CODE8, CODE9, CODE10, CODE11 e CODE_12___ vinculando a um evento de alteração. Usar um numerador/denominador inteiro evita erros de arredondamento repetidos ao dividir ainda mais ou agregar em vários titulares de direitos.
Proveniência e cadeia de auditoria
Armazene payloads de origem brutos, mas mantenha-os separados de junções canônicas. Persista o payload DDEX ERN/CWR/PRO de entrada em um armazenamento bruto ou um arquivo ___CODE0 compactado e referencie-o com CODE1. Mantenha uma tabela de CODE_2___ que registra quem ingeriu ou alterou a participação, por que (ID do acordo, revogação, correção) e um hash do payload bruto para que você possa provar a mensagem exata usada para calcular uma divisão.
Trade-off a aceitar: a retenção de payload bruto aumenta o armazenamento e aumenta as preocupações com a privacidade; compacte e nivele payloads mais antigos para armazenamento frio, mas nunca exclua o ponteiro da linha canônica. Excluir a proveniência mata a reconciliação forense e a defesa legal.
Cálculo de divisões pagáveis: para calcular uma divisão para uma determinada data de reprodução e território, consulte as participações onde effectiveFrom <= playDate < effectiveTo e o território corresponde, então some as frações aplicáveis agrupadas por função do beneficiário. Prefira fontes autoritativas por tipo de direito — use divisões registradas na PRO para royalties de execução e contratos de editor musical para mecânicos quando surgirem discrepâncias.
Exemplo concreto: um compositor atribuiu a edição musical ao Editor Musical A (exclusivo) de ___CODE0 até uma reversão em CODE1. Você mantém duas linhas de CODE2: uma com CODE3 proveniente do acordo de edição musical original e uma segunda começando em CODE_4___ proveniente do aviso de reversão (ERN ou acordo). Uma reprodução em 2019-05-01 escolhe a primeira linha; uma reprodução em 2021-03-01 escolhe a segunda.
Modo de falha comum: sobrescrever a participação anterior em vez de fechá-la. Na prática, isso faz com que as consultas de royalties históricas sejam irreproduzíveis e cria disputas de auditoria. Sempre adicione uma nova linha com limite de tempo e marque a linha antiga como fechada.
- Resolução de conflitos: implemente um mapa de autoridade de origem classificado (PRO > Editor Musical > Gravadora > Agregador) e use
confidenceScoremais classificação de origem para escolher em qual fonte confiar para cada tipo de direito. - Indexação: crie um índice composto em ___CODE0 e considere o particionamento por CODE1 ou CODE_2___ para catálogos grandes.
- Campos derivados: armazene um
computedSharedecimal normalizado para matemática de pagamento rápida, mas recalcule quando a proveniência ou o numerador/denominador mudar.
| Campo | Propósito |
|---|---|
| shareNumerator / shareDenominator | Propriedade fracionária exata para evitar a cascata de arredondamento |
| effectiveFrom / effectiveTo | Intervalo de tempo para o qual a declaração de propriedade se aplica |
| sourceSystem / sourceRecordId | Link para ERN/CWR/Acordo bruto para auditoria e rastreamento legal |
| confidenceScore | Sinalizador operacional para revisão humana e regras de reconciliação |
5. Mapeamento para Padrões de Mensagens da Indústria e Padrões de Ingestão
O mapeamento direto para padrões de mensagens não é opcional — é a maneira mais prática de reduzir o trabalho de reconciliação e capturar a proveniência. Projete sua ingestão para tratar DDEX ERN/RIN, CWR e exportações PRO como documentos de origem autoritativos, não apenas linhas de dados a serem analisadas e descartadas.
Distinção chave: use ___CODE0 para registro de recursos e metadados, CODE1 para atualizações de direitos e uso e exportações CODE_2___/PRO para registro de obras em massa onde DDEX não está disponível. Na prática, RIN carrega declarações relevantes para direitos, enquanto ERN fornece os metadados de recursos canônicos; ambos devem ser preservados como payloads brutos para auditorias. Consulte DDEX, orientação da CISAC ISWC e IFPI sobre identificadores de gravação em IFPI.
Estágios práticos do pipeline de ingestão
- Validar: verificações de esquema e assinatura de mensagem onde disponível; rejeitar ERN/RIN malformado antecipadamente.
- Normalizar: canonicalizar formatos de identificador (remover separadores, ISWC/ISRC em maiúsculas), normalizar nomes e códigos de território.
- Enriquecer: procurar ISWC/ISRC/IPI ausentes em relação aos registros; anexar impressões digitais acústicas quando as gravações estiverem presentes.
- Corresponder e pontuar: correspondência primeiro por identificador, fallback para correspondência difusa de metadados com pontuação de confiança.
- Regras de mesclagem: aplicar prioridade de origem e versionamento; manter registros anteriores como declarações com limite de tempo em vez de sobrescrever.
- Persistir payload bruto: armazenamento bruto somente anexado ou coluna JSONB com ___CODE0, CODE1 e CODE_2___.
- Emitir registros derivados: criar linhas canônicas de Obra/Gravação/Participação de Propriedade e indexar para consultas.
Tradeoff e limitação: as atualizações de streaming RIN funcionam bem para reconciliação quase em tempo real, mas aumentam a complexidade em torno da idempotência e da ordenação. Os arquivos CWR em lote são mais simples de processar, mas chegam obsoletos e carecem de granularidade no nível da gravação. A maioria dos sistemas de produção usa híbrido: streaming para atualizações, reconciliação de lote periódica em relação a arquivos em massa.
Exemplo concreto: um agregador envia um ERN sem ISWC, mas com funções de colaborador e porcentagens de participação. Seu pipeline deve validar o ERN, enriquecer consultando os registros CISAC/IPI e ISWC, criar registros de Participação de Propriedade referenciando o sourceRecordId ERN original e armazenar o payload ERN em uma tabela bruta JSONB para que um auditor possa reproduzir as decisões de enriquecimento e correspondência posteriormente.
Campo canônico -> Mapeamento DDEX (campos comuns)
| Campo canônico | Caminho DDEX ERN/RIN | Notas / tratamento |
|---|---|---|
| Work.title | WorkTitle / workTitle | Normalizar espaços em branco e diacríticos; armazenar original no payload bruto |
| Work.iswc | WorkReference / WorkID onde WorkIDType = ISWC | Enriquecer quando ausente; validar checksum |
| Recording.isrc | SoundRecordingReference / SoundRecordingID onde IDType = ISRC | ISRC frequentemente atribuído pela gravadora; tratar como correspondência de alta confiança |
| Contributor.role + IPI | ContributorList / Party / PartyId (IPI/ISNI) | Mapear para registros de Parte; fallback para correspondência baseada em nome se IPI ausente |
| OwnershipShare | ContributorList / Share / Percentage ou Split | Converter para numerador/denominador; registrar fonte ___CODE0 e CODE1___ |
Não confie apenas nos campos de porcentagem. Converta para numerador/denominador e retenha a string de porcentagem original da mensagem para evitar disputas de arredondamento durante os cálculos de royalties.
Julgamento: priorize preservar mensagens de origem e proveniência em vez de tentar uma resolução automatizada perfeita no momento da ingestão. IDs aplicados incorretamente e funções de colaborador inconsistentes são os modos de falha usuais; manter a mensagem bruta e um registro de correspondência baseado em pontuação determinística permite que você corrija os mapeamentos sem perder a rastreabilidade. Próxima consideração: defina a tabela de prioridade de origem e as chaves de idempotência antes de processar seu primeiro feed.
6. Padrões de Implementação: Modelos Relacionais, de Documento e de Gráfico com Exemplos
Ponto direto: escolha o modelo de armazenamento que corresponda à carga de trabalho: use um núcleo relacional para contabilidade e registros canônicos, documentos JSONB para ingestão e proveniência e um gráfico para exploração de relacionamento — e aceite que uma arquitetura híbrida é o resultado realista para sistemas de direitos musicais de produção.
Núcleo relacional (o que armazenar e por que)
Força relacional: As garantias ACID, junções previsíveis e auditabilidade tornam o RDBMS o armazenamento primário certo para tabelas ___CODE0, CODE1, CODE2, CODE3 e semelhantes a livros-razão. Defina CODE4 com numerador/denominador, CODE5/CODE6, CODE7 e CODE8 para preservar a proveniência. Exemplo de linha DDL: CODE9___
Camada de documento (Postgres JSONB para ingestão e desnormalização)
Força do documento: JSONB lida com DDEX ERN bruto, payloads de origem completos e registros canônicos desnormalizados para leituras rápidas. Armazene payloads brutos em ___CODE0 e snapshots canônicos em CODE1 como JSONB. Use um índice CODE2 em CODE3 e índices de caminho para CODE_4___ para acelerar o enriquecimento. Isso mantém o modelo relacional canônico pequeno, preservando os detalhes forenses.
Camada de gráfico (Neo4j para travessia e descoberta)
Força do gráfico: use um gráfico para consultas transitivas de vários saltos que são estranhas em SQL — encontre todas as gravações que sampleiam uma obra, descubra redes de editores musicais ou calcule o alcance do colaborador. Armazene divisões de propriedade nas arestas: ___CODE0. Exemplo de Cypher: CODE1___.
- Índices a adicionar: btree em ___CODE0, btree em CODE1, GIN em CODE2, índice parcial em CODE3 onde CODE_4___ para pesquisas de propriedade atuais
- Padrão de sincronização: grave primeiro no relacional para operações financeiras, espelhe JSONB desnormalizado para APIs de leitura e envie assincronamente alterações de relacionamento para o gráfico com um fluxo de eventos
| Modelo | Quando usar | Limitações |
|---|---|---|
| Relacional (Postgres) | Contabilidade, reconciliação, fontes canônicas da verdade | Travessias de relacionamento complexas tornam-se caras em escala |
| Documento (JSONB) | Retenção de payload bruto, leituras desnormalizadas rápidas, campos flexíveis de esquema | Mais difícil de impor restrições entre documentos e normalização de participação |
| Gráfico (Neo4j) | Exploração, cadeias de amostragem, redes de editores musicais, consultas de linhagem | Não é ideal para livros-razão financeiros ou agregações analíticas em massa |
Exemplo concreto: para responder onde os royalties devem fluir para uma gravação sampleada, junte recordings -> work_recording_map -> ownership_shares em SQL para calcular as divisões para o período de pagamento, enquanto usa uma travessia de gráfico para exibir todas as obras sampleadas upstream e suas redes de editores musicais para revisão humana. Na prática, esse padrão de consulta híbrida reduz os erros de reconciliação e mantém os pagamentos auditáveis.
Próxima consideração: defina contratos de sincronização claros e eventos idempotentes entre os sistemas antes de implementar a pilha híbrida — registros de propriedade incompatíveis entre os armazenamentos são o maior modo de falha operacional.
7. Reconciliação, Heurísticas de Correspondência e Considerações Operacionais
Afirmação direta: A reconciliação não é um algoritmo único — é um pipeline operacional com estágios mensuráveis, modos de falha e pontos de verificação humana. Trate a correspondência como um fluxo de trabalho projetado: caminhos rápidos determinísticos, caminhos lentos probabilísticos e um loop de revisão manual auditável.
Prioridade e limites de correspondência
- Correspondência exata do identificador: ISWC para obras, ISRC para gravações, IPI para partes. Aceitar e vincular automaticamente quando os identificadores e a autoridade de origem corresponderem.
- Correspondência de metadados de alta confiança: Título normalizado + conjunto de colaboradores (preferir IPI) + janela de duração. Use para aceitação automática somente quando a confiança > 0,95.
- Impressão digital acústica: Confirmar ou desambiguar gravações quando os IDs estiverem faltando. As impressões digitais são poderosas, mas podem confundir covers ou remasterizações.
- Correspondência difusa / ML: Use como um sinal de classificação de último recurso; sempre exiba a confiança e a proveniência e coloque na fila abaixo de um limite estrito.
- Revisão manual: Para medleys, samples ou participações conflitantes; garanta que os revisores vejam payloads de origem completos (armazene ERN/CWR bruto) e histórico de mesclagem anterior.
Insight prático: A normalização do título importa mais do que você pensa. Normalize unicode, remova o ruído textual (feat, tags de remix), colapse espaços em branco e compare com a similaridade de trigrama mais ponderação do colaborador. Isso reduz os falsos positivos de pequenas diferenças de pontuação sem ativar o ML caro.
| Heurística | Intervalo de confiança típico | Ação | ID exato (ISWC/ISRC + IPI) | 0,99–1,00 | Vincular automaticamente; registrar proveniência |
|---|
AUTOR

Charly
Carlos Palop é um experiente especialista em edição musical, especializado em gestão de direitos e distribuição de royalties, garantindo que as obras dos artistas sejam protegidas e geridas de forma rentável. A sua experiência estratégica e o seu compromisso com práticas justas fizeram dele uma figura de confiança na indústria.



